Performance guide
A major goal of Bloop as a build server for the Scala programming language is to be as fast as possible, by default, with no sacrifices in correctness or compromises in user experience. In spite of these constraints, Bloop is in fact as fast as or faster than the most popular build tools in the Scala ecosystem.
However, it is easy to go astray without an appropriate set of tools that identify regressions and measure build performance objectively. Builds stress their use of a toolchain uniquely, so it is necessary these tools are not only used during development but by users wishing to keep their build performance in check.
This guide explains the tools Bloop provides users to:
- Get familiar with the performance characteristics of project builds
- Compare the performance of Bloop with that of other tools compiling Scala code
- Modify a complicated build to optimize build times
For the moment, this guide focuses mostly on compilation performance. In the future, it will be expanded to cover testing and running.
Analyze build performance characteristics
Before analyzing performance numbers analytically, let's build a precise model of the structure of your build, its characteristics and the consequences of those in the overall build performance. A quick way to build such model is to use our Zipkin integration.
Analyze build traces in Zipkin
Zipkin is a distributed tracing system that gathers timing data and it's often used to troubleshoot problems in microservice architectures. Bloop integrates with Zipkin because it:
- Installs quickly in any system
- Displays build traces nicely in a hierarchical web user interface
- Allows persisting build traces to databases such as Cassandra
- Has an extensible design to:
- Launch and connect to remote server instances
- Allow third-parties to build in-house tooling (such as analytics tools)
Install and run zipkin
To install Zipkin, follow the installation steps in the
Zipkin Quickstart guide. After following
the guide, you should have a live Zipkin instance running at
http://localhost:9411/zipkin/.
Use case: akka/akka
We can obtain some compilation traces for the akka project by:
- Installing and running Zipkin as described above
- Compiling the
akka/akkabuild with Bloop right away
To enable tracing in Bloop you need to add -Dbloop.tracing.enabled=true to the BLOOP_JAVA_OPTS
environment variable or bloop.java-opts property when starting the server. If you are using Metals you
can also update the metals.bloopJvmProperties setting and run the Restart build server command. A Bloop
server restart is required because by default Bloop has it disabled. When the property is
set Bloop will detect Zipkin running in the default localhost address
automatically and enable tracing. You can point to another local or remote
Zipkin server by setting the url to the zipkin.server.url system property.
This last operation does also requires restarting the server.
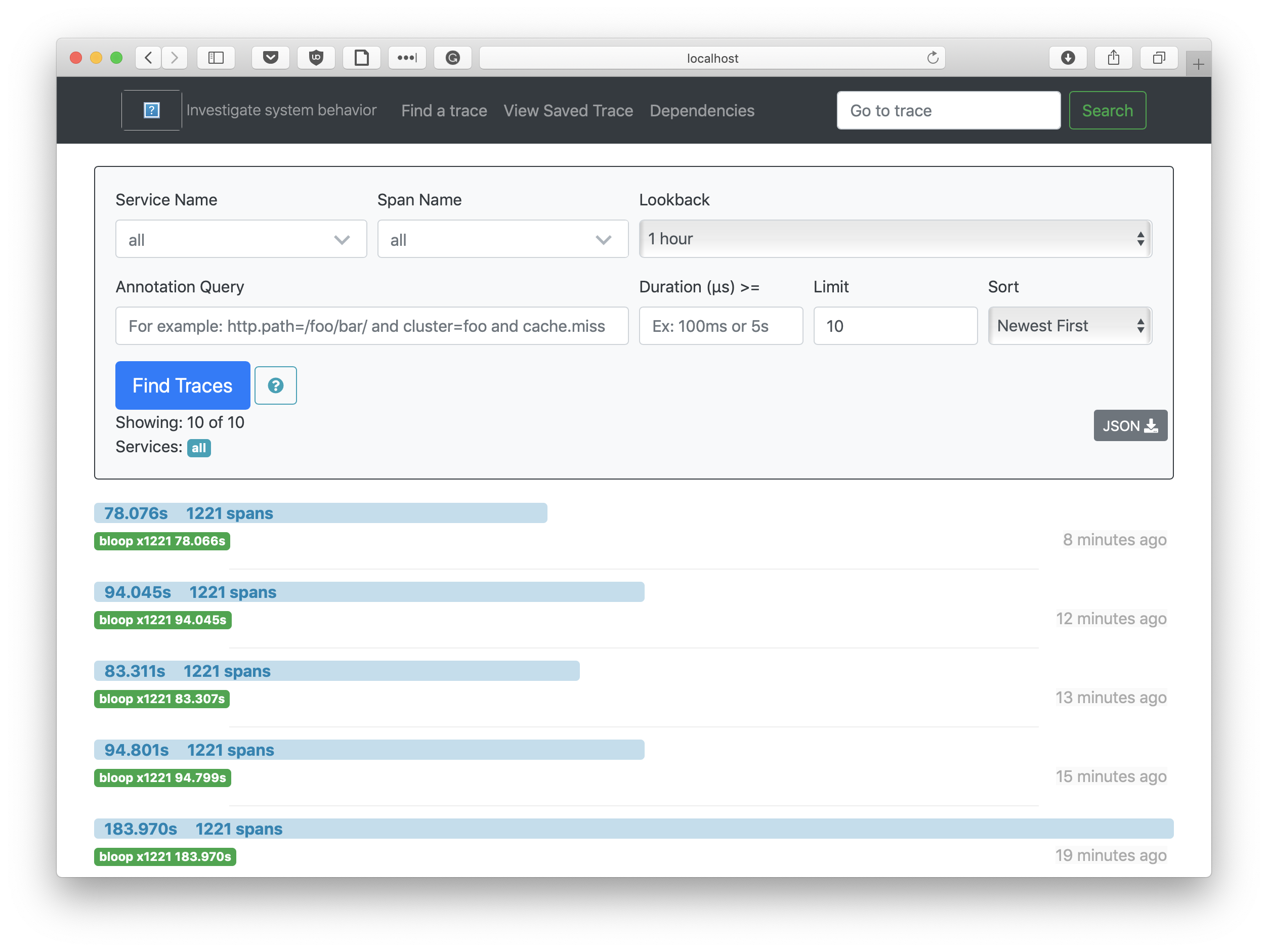
The image above shows the Zipkin UI after tracing some full compilations of
akka in commodity hardware. Note that we have sorted by "Newest First", so the
higher a trace is the more recent it is. We clearly see the JIT inside the Bloop
server getting hotter and hotter with every iteration.
However, how can Zipkin help us create a precise model of our build? Let's click on a trace to find out.
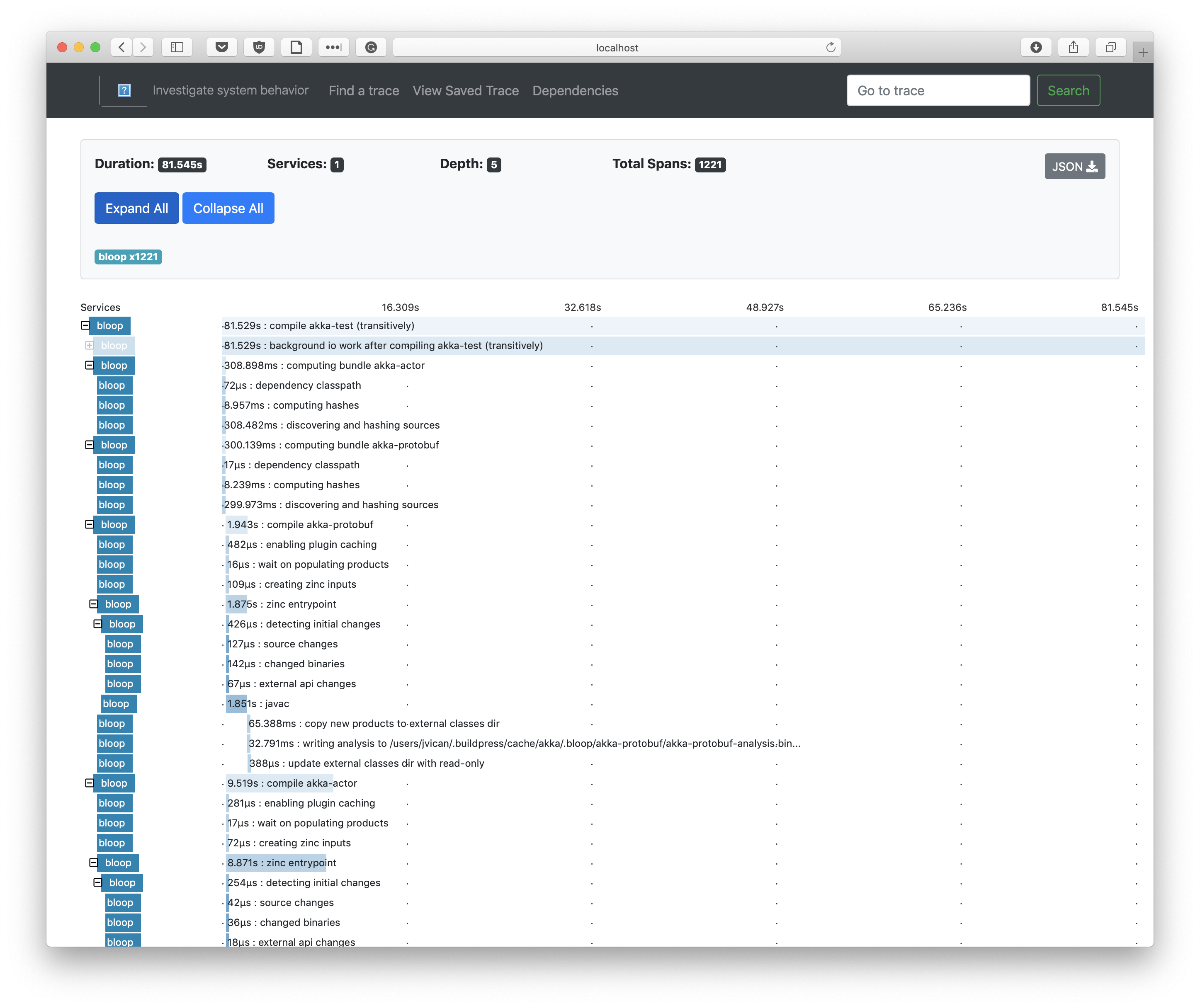
The hierarchical UI of the traces help us visualize, among others:
- What the completion time of every task is
- What are the dependencies among all Bloop tasks
- What are the number of tasks running in parallel at any given point
- What is the dependency graph of your build
- Which projects are blocked by others
Having visual help to answer these questions is invaluable to get a feeling of what we're optimizing and what can be optimized. For many of us, visualizing is the path to understanding!
If you don't know where to start, browse all the running tasks and look for surprising behaviours in your build. This is a great way to start asking questions and spot build invariants slowing down compilation times.
The Zipkin UI is rich and featureful with lots of filtering and inspection capabilities. It's recommended you play around with the UI to know how to effectively use the build traces to step up your profiling game.
Prepare to run the benchmarks
Build traces are a great way to visualize build timings and spot expensive tasks. However, we sometimes want a more precise and granular way of reasoning about our build performance.
This precision is often required when we're making changes to our builds for the sake of performance and we want to show our team how good the change we've implemented is. For that, we need a reliable numerical analysis where we control for variables such as error in our measurements or a mechanism to compute statistical data such as average time and percentiles.
To benchmark Bloop in your build, Bloop provides a JMH battery of benchmarks you can run in your build as well as several other benchmarks for other build tools such as sbt.
If you're going to go the extra mile to collect reliable benchmark data, let's remember a few best practices to keep in mind before jumping to running the benchmarks.
Control the benchmark environment
Benchmark data is as good as your system setup to minimize noise is.
If the machine where you run the benchmarks is used by other process, is not correctly configured to reduce noise or doesn't compile your project with certain degree of reproducibility, invest time to stabilize it.
- Disable NUMA.
- Disable Turbo Boost and set CPU frequency manually.
- Disable the cron scheduler or similar applications.
- Keep the running background process to a bare minimum.
- Tweak operating system details to avoid virtual memory issues, avoid lazy IO, etc
Take some inspiration from this Bash script we use for our Linux benchmarking machine.
It's legit to ignore any of these steps if, for example, the impact of your changes would be higher by enabling NUMA/Turbo Boost or you want to collect more "realistic" benchmark data that resembles better the noisy machines developers compile in.
Remember, performance is not composable!
Compare apples-to-apples
It's really important that you know what you're comparing and how.
Please think carefully about it before running any benchmarks, especially if you intend to compare the benchmark numbers with those from another tool.
For example, a common mistake is to benchmark Bloop after importing the build with Metals and then compare the results with compilation numbers from say, gradle or sbt.
When Metals imports a build or connects to Bloop, it changes scalac options and adds compiler plugins that can slow down compilation considerably. So, if you are comparing numbers in this scenario, you are not comparing apples-to-apples.
Even when comparing Bloop with other build tools, it's important to realize that Bloop has a head advantage with regards to other tools as it's a highly optimized server for only three build tasks whereas other build tools enable you to do much more.
Put your numbers into perspective when comparing, for example, the performance of no-op compilations, the time to warm up a hot compiler or the time to compile your whole build. Bloop can be faster at compiling, testing or running but if your developer workflow doesn't require any of those often, then maybe it's not a good fit for you.
Remember, be aware you benchmark the same thing and check that build definitions are unchanged!
Benchmark compile times in your build
Set up the benchmark suite
Bloop JMH benchmarks are not yet published in Maven Central. You first need to follow the CONTRIBUTING guide to set up the Bloop repository.
Then, checkout the version of Bloop you want to benchmark with
git checkout v$BLOOP_VERSION. Unless you manage your own Bloop version
internally, you should always default to the latest release version.
The benchmarks are located in the benchmarks/ directory and can be run via the
sbt-jmh setup in Bloop's build. You can navigate to HotBloopBenchmark to
have a look at the source code of the benchmark. By default, the JMH benchmark
launches a new JVM to benchmark compilations with a specific set of standard JVM
options.
Use case: akka/akka
Run benchmarks for bloop
Here's a list of the steps to benchmark akka/akka:
Remove all projects in
bloop-community-build.buildpressand add your project coordinates.- For example, we add akka with a line like
akka,https://github.com/akka/akka.git#74ad005219770552d0a7c72c61394f88ebae3b13.
- For example, we add akka with a line like
Run
sbt exportCommunityBuildin Bloop's sbt build.exportCommunityBuildinvokesbuildpress, a tool that given a URI in your file system it attempts to export the project. It currently only supports sbt.
If you cannot use buildpress because your build tool is not sbt, the process to extract your build to sbt requires manual intervention or your project is not available in a git URI, then modify
HotBloopBenchmarkand configureconfigDirto point to the.bloopdirectory of your build.- When buildpress is done, it will have cloned and exported your project
under
$HOME/.buildpress/cache.
benchmarks/jmh:run .*HotBloopBenchmark.* -wi 7 -i 5 -f1 -t1 -p project=akka -p projectName=akka-test- It runs the bloop benchmark on the akka/akka build.
- It runs 7 warmup iterations and 5 benchmark iterations.
- It only runs the benchmarks once (one fork).
Wait for JMH to finish the benchmark and analyze its results!
If you have any questions regarding the benchmark infrastructure, come ask us in our Discord channel.
Compare performance numbers with sbt
You can use the HotSbtBenchmark to compare performance numbers between bloop
and sbt.
Compare performance numbers with other tools
You can copy-paste and modify an existing benchmark to benchmark compilation in your favorite build tool.
Grafana support
Our benchmark suite can send benchmark data points to Grafana. Look at the
source code of our benchmarks and
our benchmark script
which an UploadingRunner to persist data points.
Speed up complicated builds
Once you're done benchmarking, you might have no idea where to start optimizing your build, even after looking at Zipkin build traces for a few minutes. "Sure, typechecking takes a long time, but what can I do to fix that?" or "Can I even optimize that expensive IO task" might be questions popping up in your mind.
That's normal, it takes time and experience to know which patterns you should be looking for. Don't feel daunted by the task; after all, practice makes perfect.
In this section, I want to elaborate on a few of actionable items I've used in the past to speed up large, complicated builds using lots of advanced Scala features. Hopefully, these actions will speed up your build too or inspire you to get you started optimizing it.
Use the latest Scala version
I cannot stress this enough, keeping up with the latest Scala version is critical to have a speedy build.
Many of the optimizing features we add in the compiler or in Bloop are only enabled in the latest releases and need each other, so the best way to ensure your build is as fast as it can be is by upgrading to the latest Scala version. For example, if you are using 2.11.11 while the latest compiler developments are in 2.13.0, you're most likely missing out on a lot of life-quality performance improvements.
Pick appropriate JVM and GC options
The best JVM options are those striking a balance between making an efficient use of your system's available resources and allowing the build server to operate at peak performance.
Learn how to tweak your options in the Build Server guide.
Here's a list of the most important JVM options. Below I elaborate only on the most critical for compilation.
Max heap size
The -Xmx<heap size>[unit] option sets the max heap size of the build server.
Most of the times it's better to leave it at the default value, but you can
configure it if you suspect the JVM is not allocating enough heap for a process
or if it's using too much.
Here are some recommended values:
- Use
-Xmx2gfor small to medium-sized builds. - Use up to
-Xmx4gfor large builds.
Use parallel gc unless you have evidence of a better one
Scala's developer toolchain is faster on Java 8 than on Java 9 or Java 11 because the garbage collectors in these different Java runtimes have changed considerably.
If you are using Java 9 or Java 11, I recommend defaulting on
-XX:+UseParallelGC which optimizes for throughput instead of latency.
As better garbage collectors are developed in future Java versions, I recommend benchmarking the fastest as well as tweaking GC-specific options. The Scala compiler is heavy on object allocations and is particularly sensitive to different optimizations in GC configurations.
Tweak the Java JIT
Using the stock JVM is a safe default. However, tools written in Scala such as
Bloop or scalac can be sped up significantly if you're willing to experiment
with configurations of the JIT compiler or alternative compilers to the stock C2
compiler.
For example, GraalVM is better at optimizing Scala code than the stock C2 compiler. Users have reported speedups within the range of 10%-50%. There are two GraalVMs available you can install:
- The Community edition (GraalVM CE), completely free.
- The Enterprise edition (GraalVM EE), only free for local development. It implements specific code heuristics on top of the Community edition to run code faster.
If you're stuck with the stock JVM, improve compilation performance in C2 by
using -XX:MaxInlineLevel=20, which tweaks the inline level from 9 (default)
to 20. Users have reported around 10%-20% faster compilation times.
Reorganize your build graph
The natural way we structure our projects and builds is rarely the friendliest to build times. Giving our builds a more fine-grained structure helps address many build time issues.
For example, let's say we look at a build graph like this. The Zipkin trace
shows that the compilation of c depends on that of b and the compilation of
b on that of a.

Then, when looking at the code of c, you realize c should not depend on b
or that you can move a little bit of code around to remote the dependency of
b. After removing the dependency, the build graph should look like this:

Such a graph shape is better than the initial one because it increases the
amount of projects that can be compiled in parallel (b can be built
concurrently to c) and improve incremental compilation's heuristics.
The less depth your build graph has, the more efficient to compile it will be. In the absence of low-hanging fruits such as the one above, the most common way to flatten out your build graph is to split up big projects into smaller units and trim down the amount of dependencies each of them has.
Identify long typechecking times
Average typechecking time can take between 40% and 70% of the whole compilation of a project. The more typechecking dominates your compilation times, the more likely is that there are compilation anomalies in your project.
If typechecking time is suspiciously high in your Zipkin build traces, put on your profiling hat and have a closer look at what uses of Scala features are more prominent.
For example, it's very likely you depend on a library that either directly or transitively uses Scala macros (such as Circe). Or maybe you define/use lots of implicits in your code.
If you use either macros and implicits, consider reading
Speeding Up Compilation Time with scalac-profiling
to get more familiar with the techniques you can use to profile and optimize
builds making a heave use of them.
If you don't see anything weird but still consider your project takes too long
to compile, please reach out to an expert in the
scala/contributors Gitter channel.
There are friendly people that might be able to help you fix the compilation
anomalies.